Text-to-Speech Synthesis
 Diagrams
Diagrams
Speech synthesis which attracts a lot of attention in communication and voice interaction systems aims to synthesize intelligible and high quality speech signals which are indistinguishable from human recordings. The realization of a spoken utterance can be categorized into three principal components: the content, the speaker and the style component. The content component refers to the linguistic content of speech (what). The speaker/voice characteristics are attributed to the speaker component (who). While the definition of style component associates with the variation of pitch, loudness and prosody (how). Style generally covers all aspects of speech that does not contribute to content information or the identification of the speaker.
Universal Vocoder
In the past, conventional statistical parametric speech synthesis (SPSS) exhibited high naturalness under best-case conditions. Hybrid synthesis was also proposed as a way to take advantage of both SPSS and unit-selection approaches. Most of these TTS systems consist of two modules: the first module converts textual information into acoustic features while the second one, i.e., the vocoder, generates speech samples from the previously generated acoustic information.
Techniques in neural vocoders involve data-driven learning and are prone to specialize to the training data which leads to poor generalization capabilities. Moreover, in multi-speaker scenarios, it is practically impossible to cover all possible in-domain (or seen) and out-of-domain (or unseen) cases in the training database. A potential universal vocoder was introduced claiming that speaker encoding is essential to train a high-quality neural vocoder.
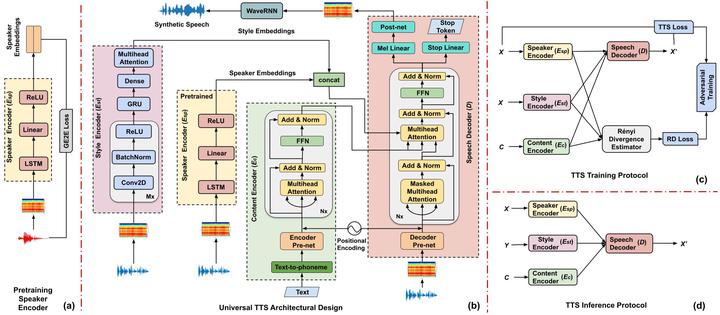
Universal TTS
A universal TTS synthesis system is able to generate speech from text with speaker characteristics and speaking style similar to a given reference signal. The major challenge for universal TTS is speaker perturbation along with style transfer. The ultimate goal is to transplant prosody from arbitrary speakers, especially in the context of zero-shot learning where only a few seconds of data is available. Towards this aim, we employ a universal TTS (UTTS) framework which consists of four major components: content encoder, style encoder, speaker encoder and speech decoder. The content encoder generates a content embedding from the text. The style encoder represents the style factors into a style embedding, while the speaker encoder provides the speaker identity in the form of a speaker embedding. Finally, the speech decoder, conditioned on all the above embeddings, synthesizes the desired target speech.
Dipjyoti Paul
Ph.D. Student | Research Scientist | Machine Learning | Deep Learning | Audio Signal Processing | Computer Vision | Conversational AI
My research interests include machine learning, deep learning, audio signal processing and image processing.