 Block Diagram
Block Diagram
Abstract
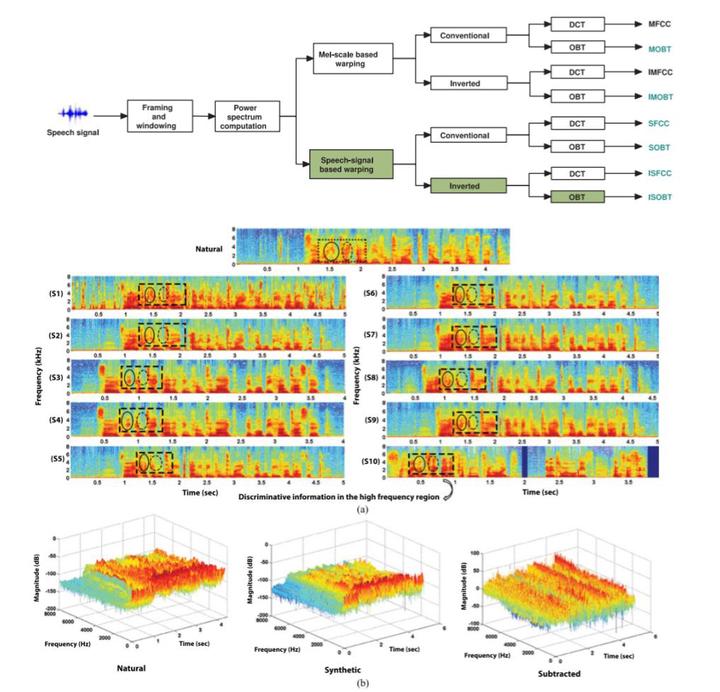
Recent advancements in voice conversion (VC) and speech synthesis research make speech-based biometric systems highly prone to spoofing attacks. This can provoke an increase in false acceptance rate in such systems and requires countermeasure to mitigate such spoofing attacks. In this paper, we first study the characteristics of synthetic speech vis-à-vis natural speech and then propose a set of novel short-term spectral features that can efficiently capture the discriminative information between them. The proposed features are computed using inverted frequency warping scale and overlapped block transformation of filter bank log energies. Our study presents a detailed analysis of antispoofing performance with respect to the variations in the warping scale for inverted frequency and block size for the block transform. For performance analysis, Gaussian mixture model (GMM) based synthetic speech detector is used as a classifier on a stand-alone basis and also, integrated with automatic speaker verification (ASV) systems. For ASV systems, standard mel-frequency cepstral coefficients are used as feature while GMM with universal background model and i-vector are used as classifiers. The experiments are conducted on ten different kinds of synthetic data from ASVspoof 2015 corpus. The results show that the countermeasures based on the proposed features outperform other spectral features for both known and unknown attacks. An average equal error rate (EER) of 0.00% has been achieved for nine attacks that use VC or SS speech and the best performance of 7.12% EER is arrived at the remaining natural speech concatenation-based spoofing attack.