 Block Diagram
Block Diagram
Abstract
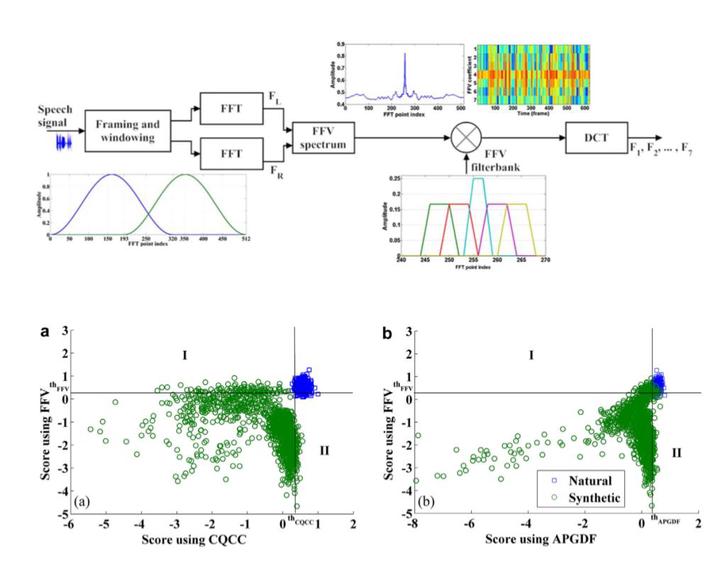
Recent works on the vulnerability of automatic speaker verification (ASV) systems confirm that malicious spoofing attacks using synthetic speech can provoke significant increase in false acceptance rate. A reliable detection of synthetic speech is key to develop countermeasure for synthetic speech based spoofing attacks. In this paper, we targeted that by focusing on three major types of artifacts related to magnitude, phase and pitch variation, which are introduced during the generation of synthetic speech. We proposed a new approach to detect synthetic speech using score-level fusion of front-end features namely, constant Q cepstral coefficients (CQCCs), all-pole group delay function (APGDF) and fundamental frequency variation (FFV). CQCC and APGDF were individually used earlier for spoofing detection task and yielded the best performance among magnitude and phase spectrum related features, respectively. The novel FFV feature introduced in this paper to extract pitch variation at frame-level, provides complementary information to CQCC and APGDF. Experimental results show that the proposed approach produces the best stand-alone spoofing detection performance using Gaussian mixture model (GMM) based classifier on ASVspoof 2015 evaluation dataset. An overall equal error rate of 0.05% with a relative performance improvement of 76.19% over the next best-reported results is obtained using the proposed method. In addition to outperforming all existing baseline features for both known and unknown attacks, the proposed feature combination yields superior performance for ASV system (GMM with universal background model/i-vector) integrated with countermeasure framework. Further, the proposed method is found to have relatively better generalization ability when either one or both of copy-synthesized data and limited spoofing data are available a priori in the training pool.