Speech frame selection for spoofing detection with an application to partially spoofed audio-data
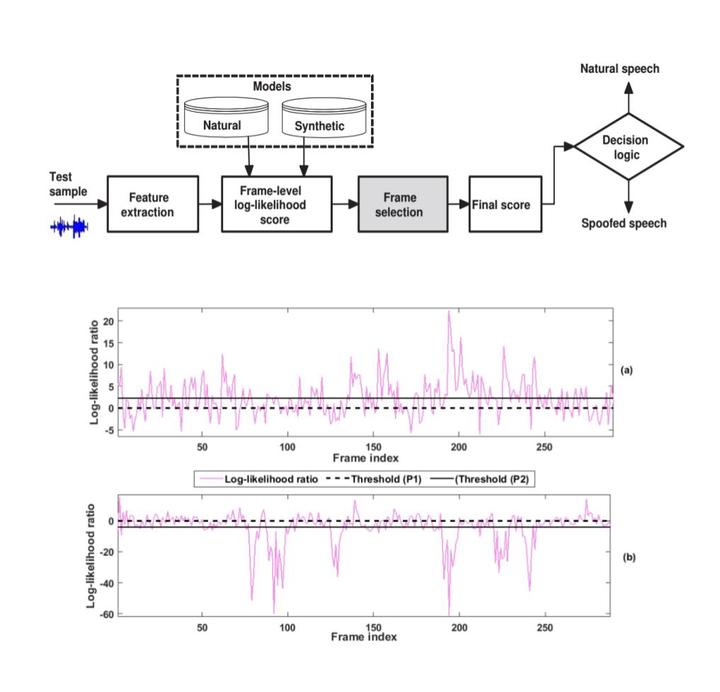 Block Diagram
Block Diagram
Abstract
In this paper, we introduce a frame selection strategy for improved detection of spoofed speech. A countermeasure (CM) system typically uses a Gaussian mixture model (GMM) based classifier for computing the log-likelihood scores. The average log-likelihood ratio for all speech frames of a test utterance is calculated as the score for the decision making. As opposed to this standard approach, we propose to use selected speech frames of the test utterance for scoring. We present two simple and computationally efficient frame selection strategies based on the log-likelihood ratios of the individual frames. The performance is evaluated with constant-Q cepstral coefficients as front-end feature extraction and two-class GMM as a back-end classifier. We conduct the experiments using the speech corpora from ASVspoof 2015, 2017, and 2019 challenges. The experimental results show that the proposed scoring techniques substantially outperform the conventional scoring technique for both the development and evaluation data set of ASVspoof 2015 corpus. We did not observe noticeable performance gain in ASVspoof 2017 and ASVspoof 2019 corpus. We further conducted experiments with partially spoofed data where spoofed data is created by augmenting natural and spoofed speech. In this scenario, the proposed methods demonstrate considerable performance improvement over baseline.