 Block Diagram
Block Diagram
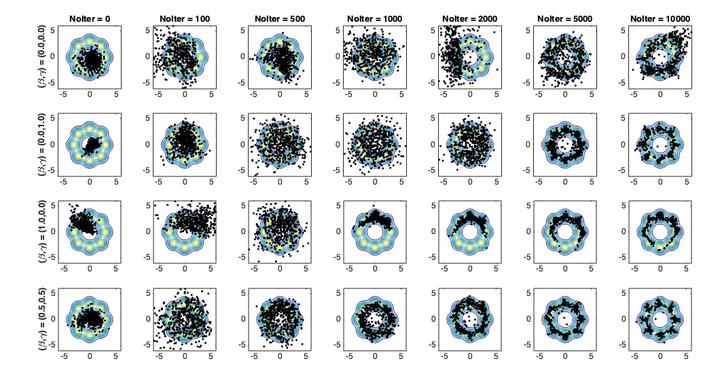
Abstract
In this paper, we propose a novel loss function for training Generative Adversarial Networks (GANs) aiming towards deeper theoretical understanding as well as improved performance for the underlying optimization problem. The new loss function is based on cumulant generating functions giving rise to Cumulant GAN. Relying on a recently-derived variational formula, we show that the corresponding optimization problem is equivalent to Rényi divergence minimization, thus offering a (partially) unified perspective of GAN losses, the Rényi family encompasses Kullback-Leibler divergence (KLD), reverse KLD, Hellinger distance and χ2-divergence. Wasserstein GAN is also a member of the proposed cumulant GAN. In terms of stability, we rigorously prove the exponential convergence of cumulant GAN to the Nash equilibrium for a linear discriminator, Gaussian distributions and the standard gradient descent algorithm. Finally, we experimentally demonstrate that image generation is generally more robust relative to Wasserstein GAN and it is substantially improved in terms of inception score when weaker discriminators are considered.